^ _ ^
Task
Difinition of machine reading compreahension
Given the context $C$ and question $Q$, machine reading comprehension tasks ask the model to give the correct answer $A$ to the question $Q$ by learning the function $F$ such that $A = F(C, Q)$
Cloze Tests
Given the context $C$, from which a word or an entity $A(A \in C)$ is removed, the cloze test ask the model to fill in the blank woth the right word or entity A by learning the function $F$ such that $A=F(C-{A})$
Multiple Choice
Given the context $C$, the question $Q$ and a list of candidate answers $A={A_1, A_2, \cdots, A_n}$, the multiple-choice task is to select the correct answer $A_i$ from $A(A_i \in A)$ by learning function F such that $A_i=F(C, Q, A)$
Span Extraction
Given the context $C$, which consists of $n$ tokens, that is $C={ t_1, t_2, \cdots, t_n }$, and the question $Q$, the span extraction task requires extracting the continuous subsequence $A$ = { $t_i, t_{i+1}, \cdots, t_{i+k}$ } from context $C$ as the correct answer to question $Q$ by learning function $F$ such that $A=F(C, Q)$
Free Answering
Given the context $C$ and the question $Q$, the correct answer $A$ in free answering task may not be subsequence in the original context $C$, namely either $A \in C$ or $A \notin C$. The task requires predicting the correct answer $A$ by learning the function $F$ such that $A = F(C, Q)$.
Deep-learning based Method
General Architecture
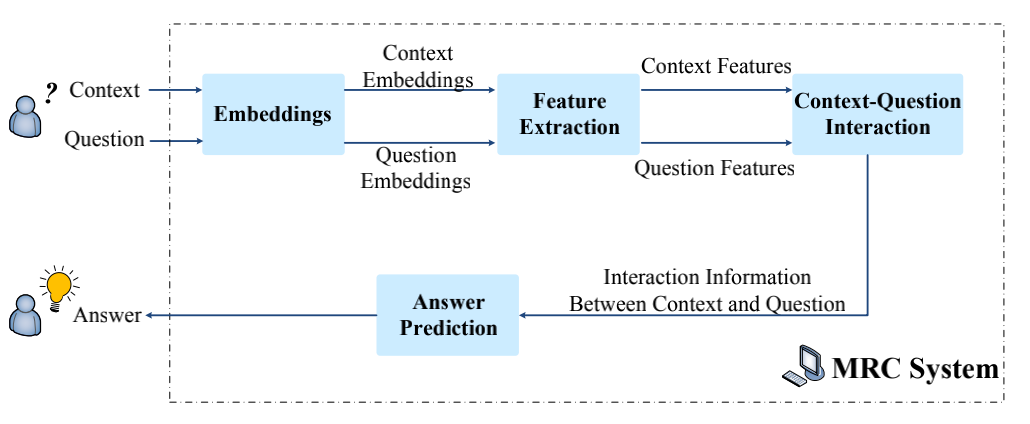
- Embeddings: change input words into fixed-length vectors.
- Classical word representation method include One-hot; Word2vec; Glove; Fastext.
- Sometimes combined with other linguistic features, i.e., part-of-speech, name entity, and question category.
- Feature Extraction: Mine contextual features from context and question embeddings
- This module is aimed at extracting more contextual information.
- Some typical deep neural networks such as CNN, RNN are used.
- Context-Question Interation: find out which parts in the context are more important to answering the question.
- The attention mechanism, unidirectional or bidirectional, is widely used in this module to emphasize parts of the context relevant to the query.
- Sometimes involves multiple hops, which simulates the rereading process of human comprehension.
- Answer Prediction: this module is highly related to different tasks
- Generation techniques are used in this module for the free answering task
Typical Deep-learning Methods
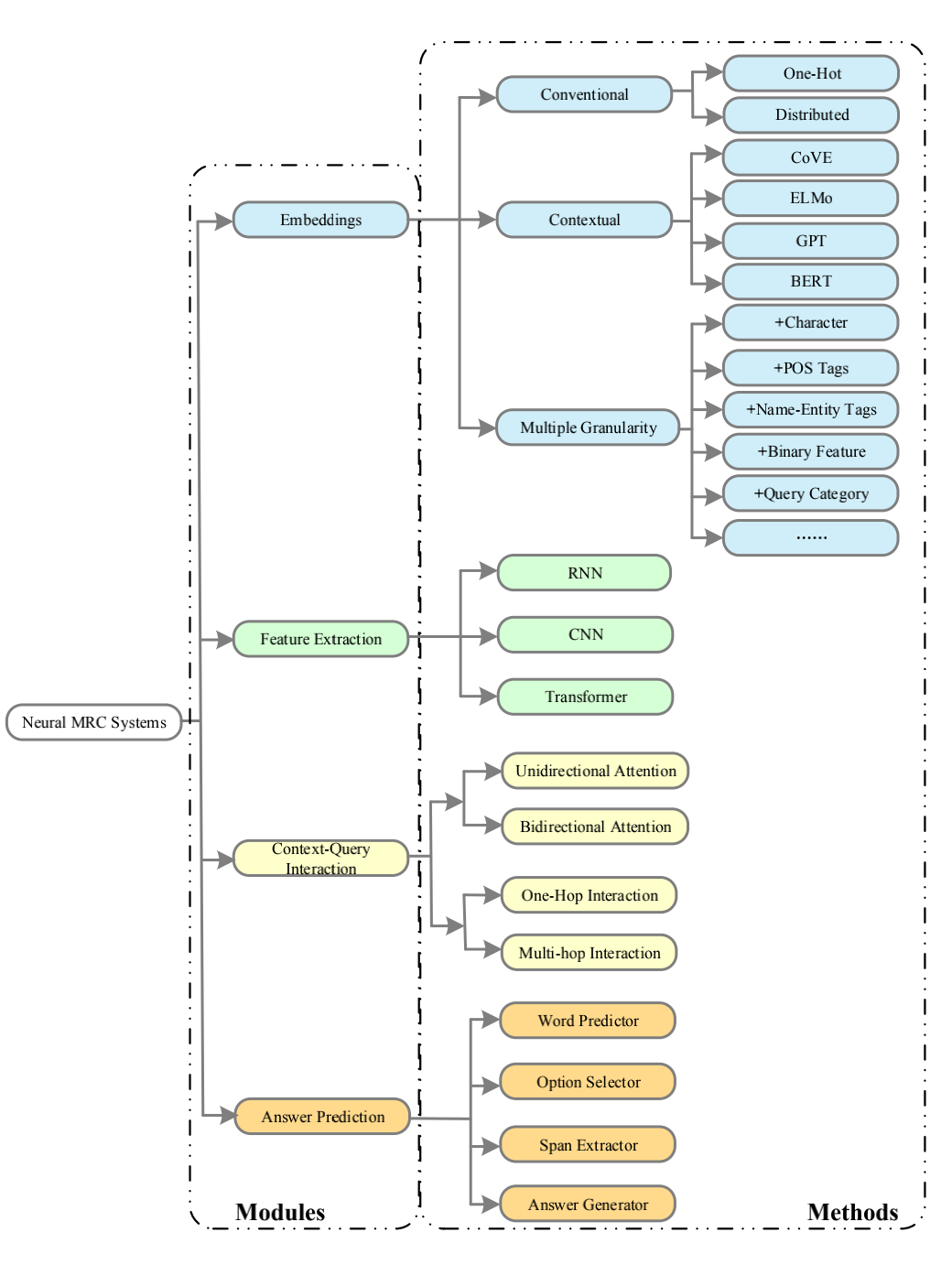
Embeddings
Conventional Word Representation
One-Hot
- Using binary vector to represent word, and the size of vector is equal to the size of vocabulary.
- Drawbacks:
- Sparse and may cause curse of dimensionality with increased vocabulary.
- Cannot represent relationships among words.
Distributed Word Representation
- Encodes words into continuous low-dimensional vectors, which reveals the correlation of words.
- Popular techniques to generate distrubuted word representation: Word2Vec、GloVe.
- Drawback: Cannot efficiently mine contextual information.
Pre-trained Contextualized Word Representation
- A vector produced by the distributed word representation of one word is constant regardless of different contexts.
- Contextualized word representations, which are pre-trained with large corpora in advance and then directly used as conventional word representations or fine-tuned according to the specific tasks.
CoVE
- The output of the encoder can be regarded as context vectors (CoVE).
- Concatenate CoVE of another task and embeddings of this task and feed them through the decoder.
- Drawbacks: Another task(e.g. Machine Translation) needs a large parallel corpus. Its performance will degrade if the training corpus is not adequate.
ELMo
- Embeddings from language models (ELMo)
- First pre-train a bidirectional language model (biLM) with a large text corpus, then collapsing outputs of all biLM
layers into a single vector with a task-specific weighting.
GPT
- Generative pre-training (GPT)
- A semi-supervised approach combining unsupervised pre-training and supervised fine-tuning.
- The basic component of GPT is a multi-layer transformer decoder that mainly uses multi-head self-attention to train the language model.
BERT
- Bidirectional encoder representation from transformers (BERT).
- With the masked language model (MLM) and next-sentence prediction task, BERT can pre-train deep contextualized representations with a bidirectional transformer.
Multiple Granularity
- Word-level embeddings pre-trained by Word2Vec or GloVe cannot encode rich syntactic and linguistic information, such as part-of-speech, affixes, and grammar.
Character Embeddings
- Character embeddings represent words at the character level.
- Character embeddings can be encoded with bidirectional LSTMs. For each word, the outputs of the last hidden state are considered to be its character-level representation.
- Moreover, word-level and character-level embeddings can be combined dynamically with a fine-grained gating mechanism.
Part-of-Speech Tags
- A part-of-speech (POS) is a particular grammatical class of words, such as nouns, adjectives, or verb.
- Labeling POS tags in NLP tasks can illustrate complex characteristics of word use and in turn contribute to disambiguation.
Name-Entity Tags
- Name entity, a concept in information retrieval, refers to a real-world object, such as a person, location, or organizations, with a proper name.
- When asking about such objects, name entities are probable answer candidates.
- The method of encoding name-entity tags is similar to that of POS tags.
Binary Feature of Exact Match (EM)
- This feature measures whether a context word is in the question.
- More loosely, partial matching to measure the correlation between context words and question words. For instance, “teacher” can be partially matched with “teach”.
Query-Category
- The types of questions (what, where, who, when, why, how) can usually provide clues to search for the answer.
- First obtain query types by counting the key word frequency. Then the question type information is encoded to one-hot vectors and stored in a table. For each query, they look up the table and use a feed-forward neural network for projection.
Feature Extraction
- The feature extraction module is often placed after the embedding layer to extract features of the context and question separately.
- It further pays attention to mining contextual information at the sentence level based on various types of syntactic and linguistic information encoded by the embedding module.
Recurrent Neural Networks
- RNNs are called recurrent as outputs in each time step depending on the previous computations.
- Applied to deal with sequential information.
- In particular, long short-term memory (LSTM), gated recurrent units (GRUs), variants of RNNs, are much better at capturing long-term dependencies than plain ones are and can alleviate gradient explosion and vanishing problems.
- The preceding and following words have the same importance in understanding the given word, bidirectional RNNs have been widly used.
The feature extraction process with bidirectional RNNs can be sorted into two types:
word-level
Feature extraction outputs for each embedding $x$ at time step $j$.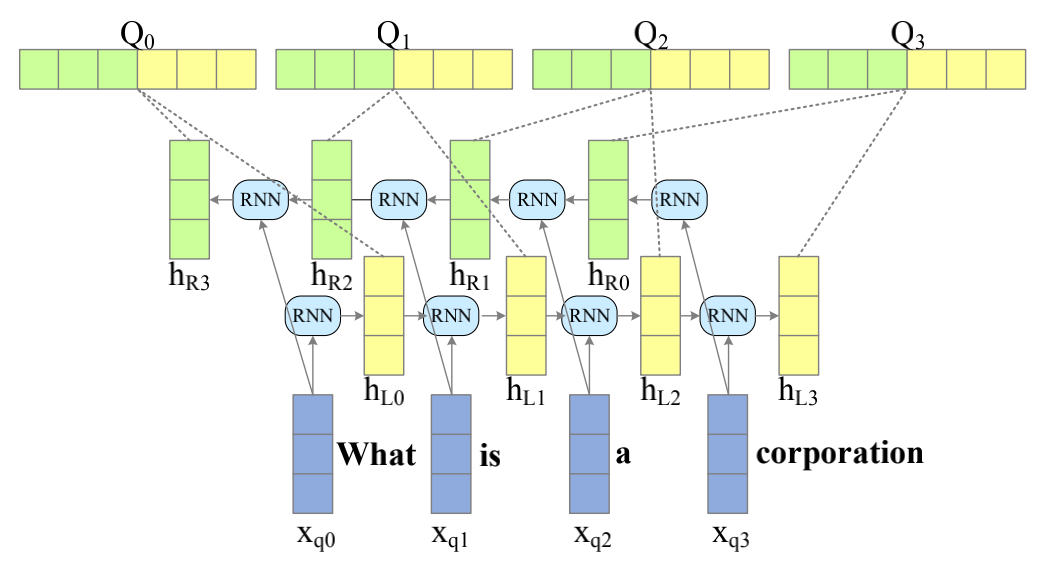
sentence-level
Sentence-level encoding regards the question sentence as a whole.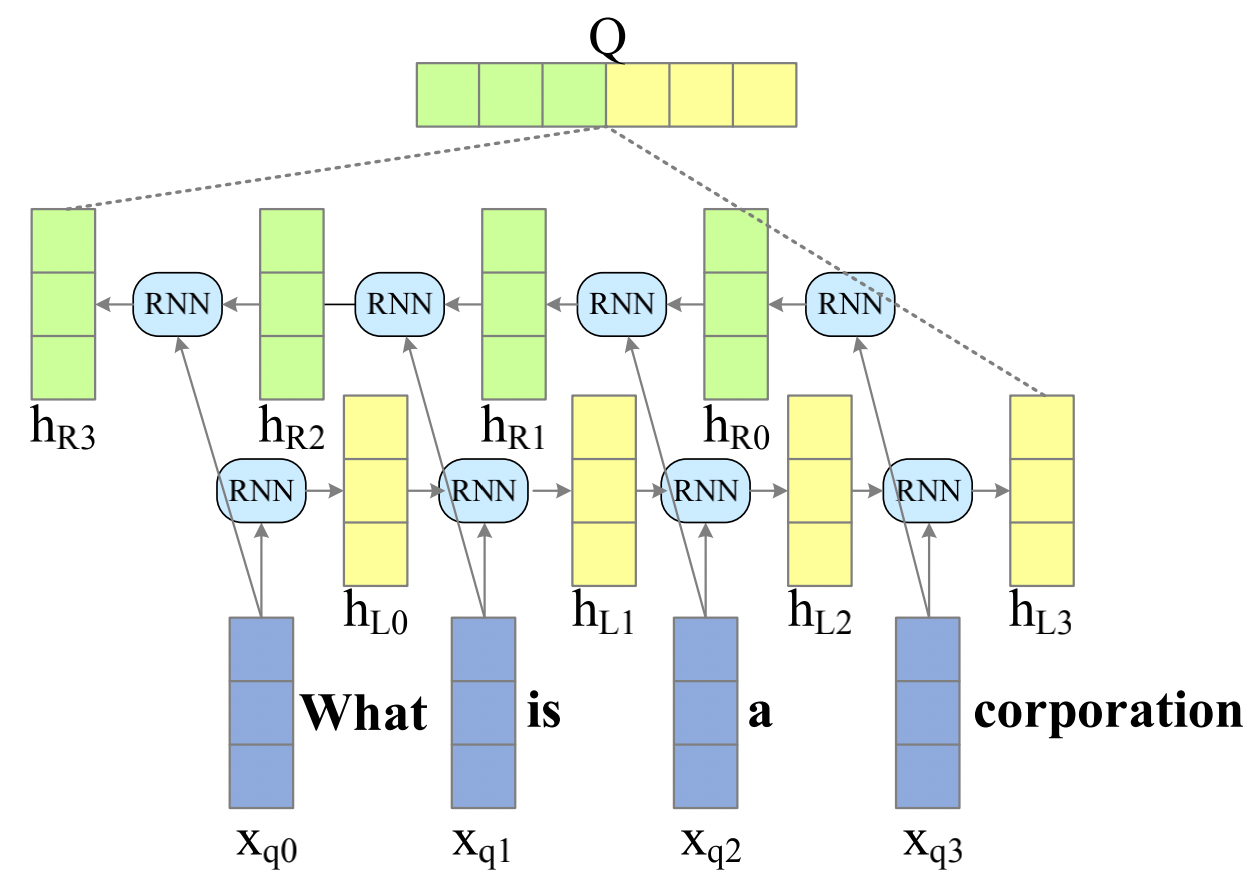
Convolution Neural Networks
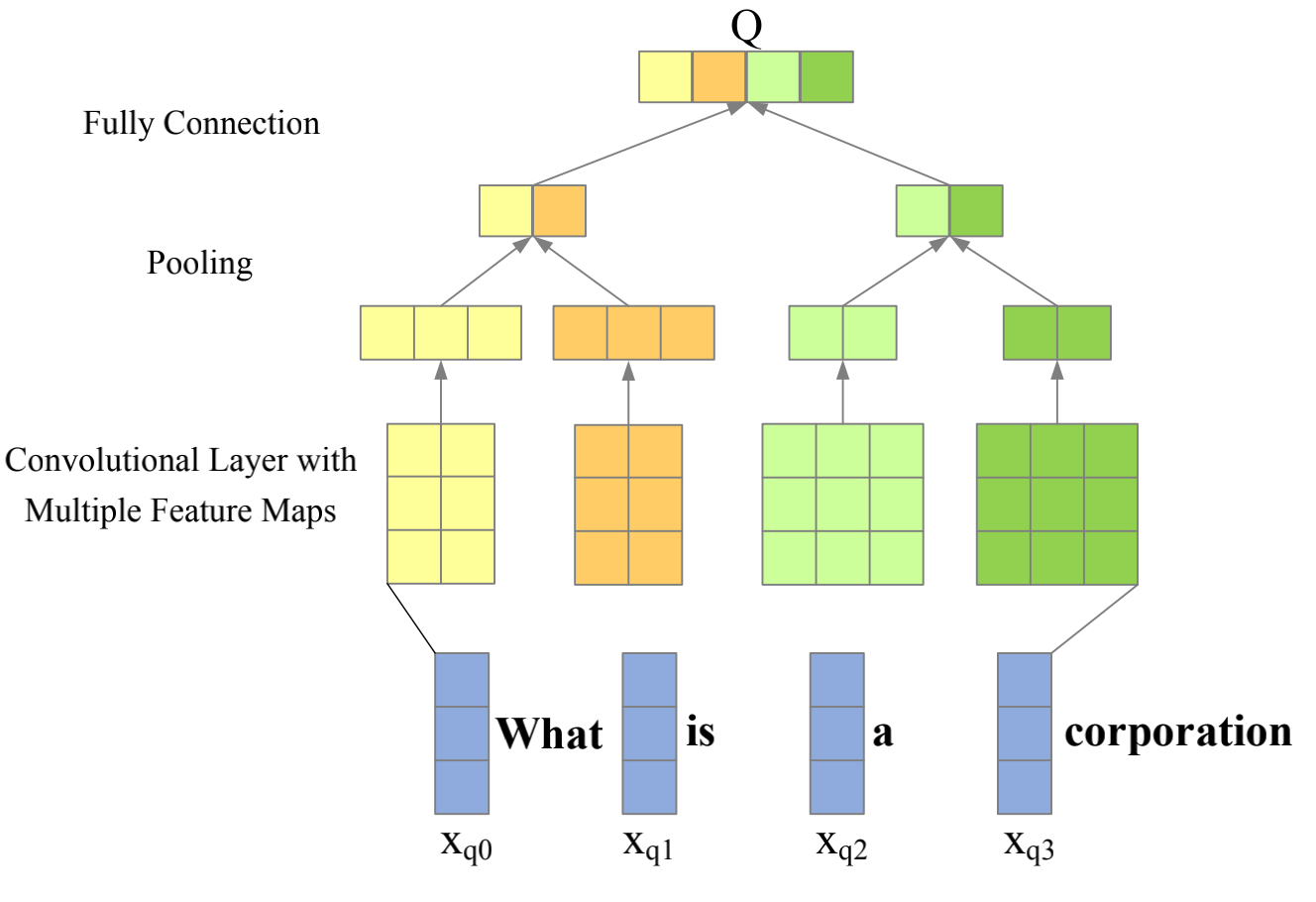
- The convolution layer has two filter sizes $f_t \times d$ with $k$ output channels, where $d$ is the dimension of word embedding.
- Each filter produces a feature map of shape $(|l| − t + 1) \times k$, where $l$ is the length of sentence.
- One major shortcoming of CNNs is that they can extract only local information but are not capable of dealing with long sequence.
Transformer
![]()
- Mainly based on the attention mechanism and multi-head self-attention.
- Add position encoding to make use of the order information.
- In practice, models usually stack several blocks with multi-head self-attention and feed-forward network.
QANet is a representative MRC model that uses the transformer. The basic encoder block of QANet is a novel architecture, which combines the multi-head self-attention defined in the transformer with convolutions.
Context-Question Interaction
Extracting the correlation between the context and the question
Unidirectional Attention
Unidirectional attention flow is usually from query to context, highlighting the most relevant parts of the context according to the question.
The similarity of each context semantic embedding $P_i$ and the whole question sentence representations Q is calculated by $S_i = f(P_i, Q)$, where $f(\cdot)$ represents the function that can measure the similarity.
After being normalized by Softmax, the attention weight for each context word is obtained.
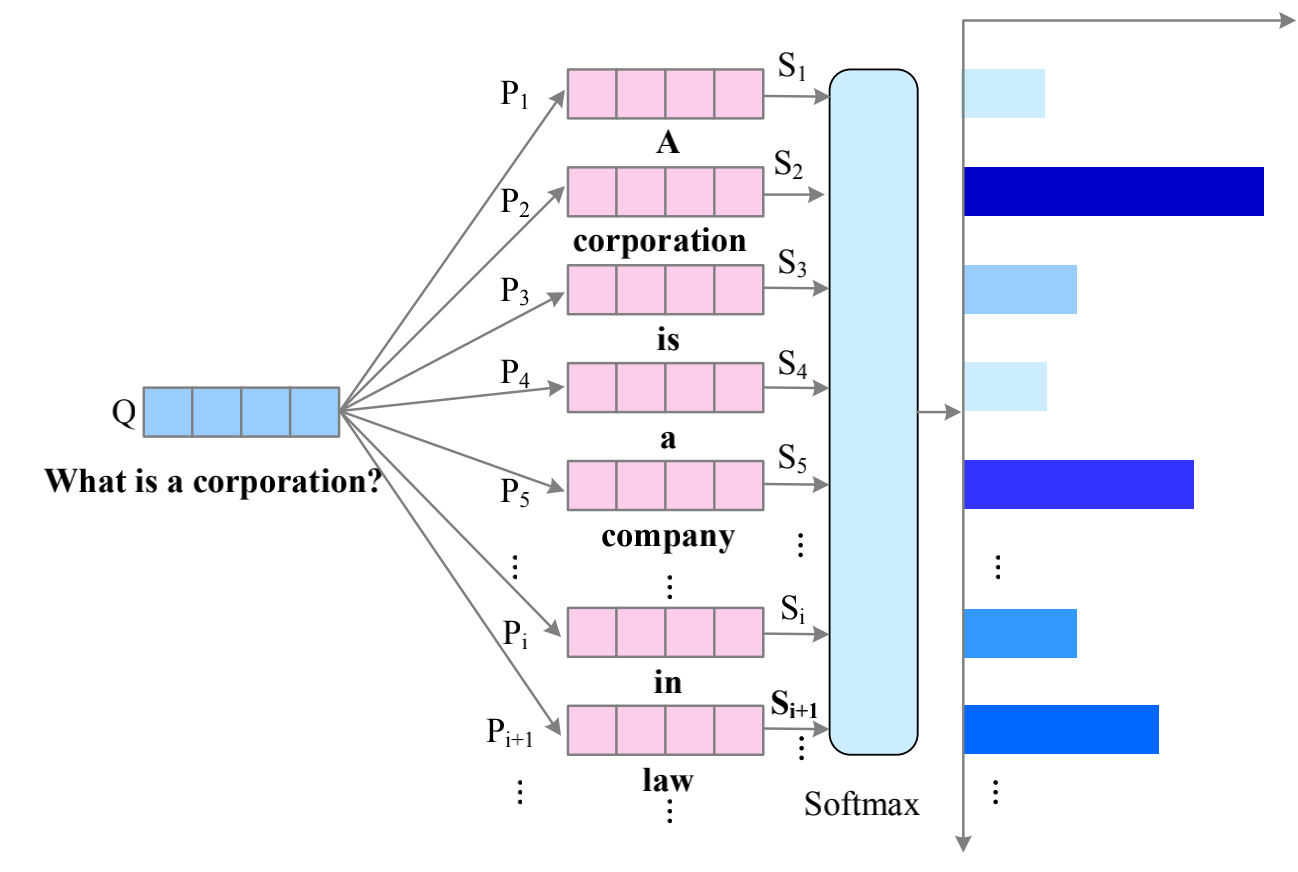
However, this method fails to pay attention to question words that are also pivotal for answer prediction. Hence, unidirectional attention flow is insufficient for extracting mutual information between the context and the query.
Bidirectional Attention
Bidirectional attention flows, not only computes query-to-context attention but also the reverse, context-to-query attention.
The process of computing bidirectional attention:
- the pair-wise matching matrix $M(i, j)$ is obtained by computing the matching scores between each context semantic embedding $P_i$ and question semantic embedding $Q_j$ (word-level).
- Then the outputs of the column-wise SoftMax function can be regarded as query-to-context attention weight $\alpha$ while context-to-query attention $\beta$ is calculated by the row-wise SoftMax function
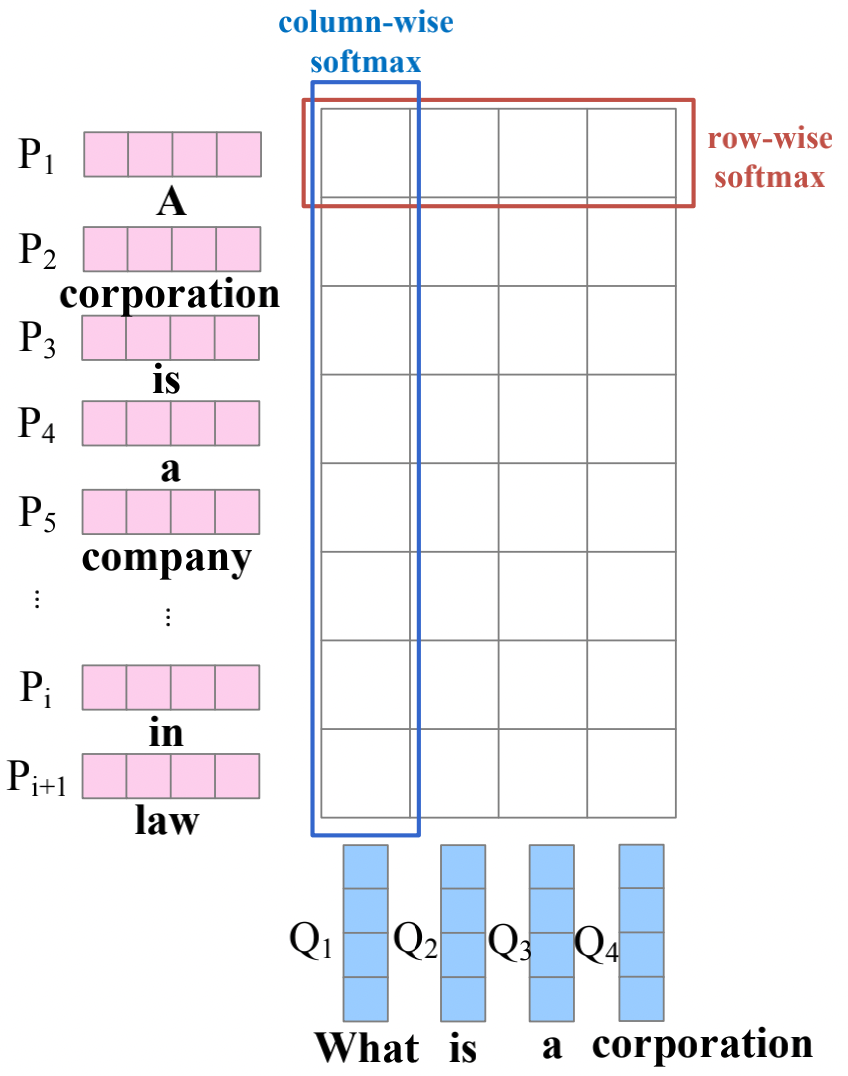
Bidirectional Attention based methods:
- AoA Reader(Attention over Attention): compute the dot product between each context embedding and query embedding to obtain a similarity matching matrix $M$. And introducing attended attention, computed by the dot product of $\alpha$ and the average result of $\bata$, which is later used to predict the answer.
- DCN(Dynamic Coattention Network)
- Bi-DAF(Bidirectional Attention Flow)
- DCN+: Using residual connections to merge coattention outputs to encode richer information for the input sequences.
One-Hop Interaction
The interaction between the context and the question is computed only once.
Although this method can do well in tackling simple cloze tests, when the question requires reasoning over multiple sentences in the context, it is hard for this one-hop interaction approach to predict the correct answer.
Multi-Hop Interaction
It tries to mimic the rereading phenomenon of humans by computing the interaction between the context and the question more than once.
Mainly methods to perform multi-hop interaction:
- Calculating the similarity between the context and the question based on previous attentive representations of context.
- e.g. Impatient Reader model: query-aware context representations are dynamically updated by this method as each query token is
read.
- e.g. Impatient Reader model: query-aware context representations are dynamically updated by this method as each query token is
- Using external memory slots to store previous memories.
- After being given the context as input, the memory mechanism stores information of the context in memory slots and then updates them dynamically.
- End-to-end version of memory networks: memory storage is embedded with continuous representations and the process of reading and updating memories is modeled by neural networks.
- MEMEN model: Stores question-aware context representations, context-aware question representations, and candidate answer representations in memory slots and updates them dynamically.
- Using hidden states to store previous interaction information.
- R-NET and iterative alternating reader (IA Reader) [14] also use RNNs to update query-aware context representations to perform
multi-hop interaction.
- R-NET and iterative alternating reader (IA Reader) [14] also use RNNs to update query-aware context representations to perform
Gate Machanism
Which can control the amount of mutual information between the context and the question, is a key component in multi-hop interaction.
The gate mechanism, which is performed by a feed-forward network, is applied to determine the degree of matching between the context and the query. Or to filter out insignificant parts in the context and emphasize the ones most relevant to the question.
Answer Prediction
The implementation of answer prediction is highly task-specific.
Word Predictor
Cloze tests require filling in blanks with missing words or entities.
- Attentive Reader: The combination of the query-aware context and the question is reflected in the vocabulary space to
search for the correct answer word. But it cannot handle situation that answer is not in the context.
Option Selector
To tackle the multiple-choice task, the model should select the correct answer from candidate options. The common way is to measure the similarity between attentive context representations and candidate answer representations.
Span Extractor
The span extraction task can be regarded as an extension of cloze tests, which requires extracting a subsequence from the context rather than a single word.
Answer Generator
With the appearance of free answering tasks, answers are no longer limited to a subsequence of the original context; instead, they need to be synthesized from the context and the question.
Additional Tricks
Reinforcement Learning
In a word, reinforcement learning can be regarded as an improved approach in MRC systems that is capable of not only reducing the gap between optimization objectives and evaluation metrics but also determining whether to stop reasoning dynamically. With reinforcement learning, the model can be trained and refine better answers even if some states are discrete.
Answer Ranker
The common process of ranker is that it extracts some candidate answers, and the one with the highest score is the correct answer.
Sentence Selector
In practice, if the MRC model is given a long document, it takes a lot of times to understand the full context to answer questions. However, finding the sentences that are most relevant to the questions in advance is a possible way to accelerate the training process.
Dataset and Evaluation Metrics
Dataset
Highlighting:
- How to construct large-scale datasets according to task requirements.
- How to reduce lexical overlap between questions and context.
Cloze Tests Datasets
- CNN & Daily Mail
- The Children’s Book Test (CBT)
- LAMBADA(Discourse aspects (LAMBADA) dataset)
- Who-did-What: Each sample is formed from two independent articles; one serves as the context and questions are generated from
the other. - CLOTH: cloze test by teachers (CLOTH)
- CliCR: A large-scale cloze-style dataset based on clinical case reports for healthcare and medicine
Multiple-Choice Dataset
- MCTest: It consists of 500 fictional stories, and for each story there are four questions with four candidate answers.
- RACE: As a multiple-choice task, RACE asks for more reasoning, because questions and answers are human-generated and simple methods based on information retrieval or word co-occurrence may not perform well.
Span Extraction Dataset
- SQuAD: The Stanford Question-Answering Dataset (SQuAD). Collecting 536 articles from Wikipedia, Rajpurkar et al, and ask crowd-workers to pose more than 100,000 questions and select a span of arbitrary length from the given article to answer the question.
- NewsQA: Articles are collected from CNN. Some questions in NewsQA have no answer according to the given context.
- TriviaQA: Gather question-answer pairs from trivia and quiz-league websites. Then they search for evidence to answer questions from webpages and Wikipedia. Finally, they build more than 650,00 question-answer-evidence triples for the MRC task.
- DuoRC: Try to reduce lexical overlap between questions and contexts in DuoRC. Questions and answers in DuoRC are created from two different versions of documents.
Free Answering Datasets
- bAbI: A well-known synthetic MRC dataset. It consists of 20 tasks, generated with a simulation of a classic text adventure game. Each task is independent from the others and tests one aspect of text understanding.
- MS MARCO: Can be viewed as another milestone of MRC after SQuAD. (1)Collected from real queries. (2)search with Bing search engine to serve as context. (3)label answers are generated by humans. (4)there are multiple answers to each question and sometimes they even conflict.
- SearchQA: Like TriviaQA. The major difference between SearchQA and TriviaQA is that in TriviaQA there is one document with evidence for each question-answer pair, while in SearchQA each pair has 49.6 related snippets on average.
- NarrativeQA: Generate question-answer pairs according to those summaries. What makes NarrativeQA special is that answering questions requires understanding the whole narrative.
- DuReader: A large-scale MRC dataset from real-world application. (1)Questions and documents are collected from Baidu. (2)It provides new question types such as yes/no and opinion.
Evaluation Metrics
Accuracy
Given $m$ questions, correctly predicts answers for $n$ question, then accuracy=$\frac{n}{m}$
F1 Score

precision = $\frac{TP}{TP+FP}$
recall = $\frac{TP}{TP+FN}$
F! = $\frac{2 \times P \times R}{P + R}$
ROUGE-L
Recall-Oriented Understudy for Gisting Evaluation, initially developed for automatic summarization.
$R_{ls} = \frac{LCS(X, Y)}{m}$
$P_{ls} = \frac{LCS(X, Y)}{n}$
$F_{lcs} = \frac{(1+\beta)^2)R_{lcs}P_{lcs}}{R_{lcs} + \beta^2 P_{lcs}}$
- $X$ is ground-truth answer with $m$ tokens;
- $Y$ is model-generated answer with $n$ tokens;
- $LCS(X, Y)$ denotes the length of the longest common subsequence of $X$ and $Y$;
- $\beta$ is a parameter to control the importance of precision $P_{lcs}$ and recall $R_{lcs}$
However, the length of candidate answers influences the value of ROUGE-L.
BLEU
Bilingual Evaluation Understudy, is widely used to evaluate translation performance.
BLEU score measures the similarity between predicted answers and ground truth:
$P_n(C, R) = \frac{\sum_i \sum_k min(h_k(c_i), max(h_k(r_i)))}{\sum_i \sum_k h_k(c_i)}$
- $h_k(c_i)$ counts the number of $k$-th n-gram appearing in candidate answer $c_i$;
- $h_k(r_i)$ denotes the occurrence number of that n-gram in gold answer $r_i$.
As the value of $P_n(C, R)$ is higher when the answer span is shorter. The penalty factor, BP, is introduced to alleviate that.
$$
BP = \left{\begin{matrix}
1, & l_c > l_r \
e^{1-\frac{l_r}{l_c}}, & l_c \le l_r
\end{matrix}\right.
$$
Finally, the BLEU score is computed as follows:
$BLEU = BP \cdot exp(\sum_{n=1}^N w_n logP_n)$
- $N$ means n-grams up to length $N$;
- $w_n$ equals $\frac{1}{N}$.
BLUE score can not only evaluate the similarity between candidate answer and ground-truth answers but alos test the readibility of candidates.
New Trends
Knowledge-Based Machine Reading Comprehension
Given the context $C$, question $Q$ and external knowledge $K$, the task requires predicting the correct answer $A$ by learning the function $F$ such that $A=F(C, Q, K)$
The key challenges in KBMRC
Relevant External Knowledge Retrieval
There are various kinds of knowledge stored in knowledge bases, and entities may be misleading sometimes because of polysemy, e.g., “apple” can refer to a fruit or a corporation.
External Knowledge Integration
Knowledge in an external knowledge base has its own unique structure. How to encode such knowledge and integrate it with representations of the context and questions remains an ongoing research challenge.
Machine Reading Comprehension with Unanswerable Questions
Given the context $C$ and question $Q$, the machine first determines whether $Q$ can be answered or not based on the given context $C$. If the question is impossible to be answered, the model marks it as unanswerable and abstain from answering, otherwise predicts the correct answer $A$ by learning the function $F$ such that $A=F(C, Q)$
Unanswerable Questions
There is a latent hypothesis behind MRC tasks that correct answers always exist in the given context. However, this does not conform with real-world application. A mature MRC system should distinguish those unanswerable questions.
SQuAD 2.0 is a representative MRC dataset with unanswerable questions.
Unanswerable Question Detection
After comprehending the question and reasoning through the passage, the MRC models should judge which questions are impossible to answer based on the given context and mark them as unanswerable.
Plausible(貌似真实的) Answer Discrimination
The MRC model must verify the predicted answers and tell plausible answers from correct ones.
Multi-Passage Machine Reading Comprehension
Given a collection of m documents $D = {D_1, D_2, \cdots, D_m}$ and the question $Q$, the multi-passage MRC task requires giving the correct answer $A$ to question $Q$ according to document $D$ by learning the function $F$ such that $A=F(D, Q)$
Massive Document Corpus
Under this circumstance, whether a model can retrieve the most relevant documents from the corpus quickly and correctly decides the final performance of readin comprehension.
Noisy Document Retrieval
Sometimes the model may retrieve a noisy document that contains the correct answer span, but it is not related to the question. This noise will mislead the understanding of the context.
No Answer
When the retrieval component does not perform well, there will be no answers in the document.
Multiple Answers
In the open-domain setting, it is common to find multiple answers for a single question.
Evidence Aggregation
In terms of some complicated questions, snippets of evidence can appear in different parts of one document or even in different documents.
Conversational Machine Reading Comprehension
Given the context $C$, the converssation history with previous questions and answers $H={A_1, A_1, \cdots, Q_{i-1}, A_{i-1}}$ and current question $Q$, the CMRC task is to predict the correct answer $A_i$ by learning the function $F$ that $A_i=F(C, H, Q_i)$
MRC requires answering a question based on the understanding of a given passage, with questions usually isolated from each other. However, the most natural way that people acquire knowledge is via a series of interrelated question-and-answer processes.
Conversational History
A follow-up question may be closely related to prior questions and answers.
Coreference Resolution(指代消解)
Coreference can be sorted into two kinds, explicit and implicit.
- With explicit coreference, there are explicit markers, such as some personal pronouns.
- By comparison, implicit coreference without explicit markers is much harder to figure out. Short questions with certain intentions that implicitly refer to previous content are a kind of implicit coreference.
Open Issues
- Limitation of Given Context
- Robustness of MRC Systems
- Incorporation of External Knowledge
- Lack of Inference Ability
- Diffificulty in Interpretation