Yann LeCun, Yoshua Bengio, Geoffery Hinton write the review of Deep Learning in 2015, published in Natrue^ _ ^
Abstrat
Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have dramatically improved the state-of-the-art in speech recognition, visual object recognition, object detection and many other domains such as drug discovery and genomics. Deep learning discovers intricate structure in large data sets by using the backpropagation algorithm to indicate how a machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer. Deep convolutional nets have brought about breakthroughs in processing images, video, speech and audio, whereas recurrent nets have shone light on sequential data such as text and speech.
Features Of Deep Learning Model:
- Composed of multiple processing Layers.
- The target of Deep Learning is to learn representations of data with multiple levels of abstraction.
- The core method of Deep Learning is backpropagation: Machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer.
Motivation
The drawback of conventional Machine-Learning: e limited in their ability to process natural data in their raw form. Required careful engineering and considerable domain expertise to design a feture extractor that transformed the raw data.(e.g image pixel –> feature vector).
Representation Learning is a set of method that allows machine to be fed with raw data and automatically discover the presentations needed.
Deep Learning methods is one of Representation Learning method with mulyiple levels of representation, obtained by composing no-linear module that each transform the representation at one low level(starting with the raw input) into a representation at a higher, abstract level.(e.g image detection: input raw pixel data(1 layer) –> detect edege at particular orientations and locations(2 layer) –> detect motifys by arrange edges(3 layer) –> assember motifys to parts of object(4 layer) –> detect object by combining parts of objects(5 layer)).
The key aspect of deep learning is that these layers of features are learned from data suing a general-purpose learning procedure.
Supervised Learning
- Collated a large data set and labelled them.
- During training, machine is shown an input and produces an output in the form of vector of scores.
- Compute an objective function that measures the errors between the output scores and the desired pattern of scores. The machine than modify its internal adjustable parameters(weight) to reduce the error. In practive, stochastic gradient descent(SGD) is used for weight modifying.
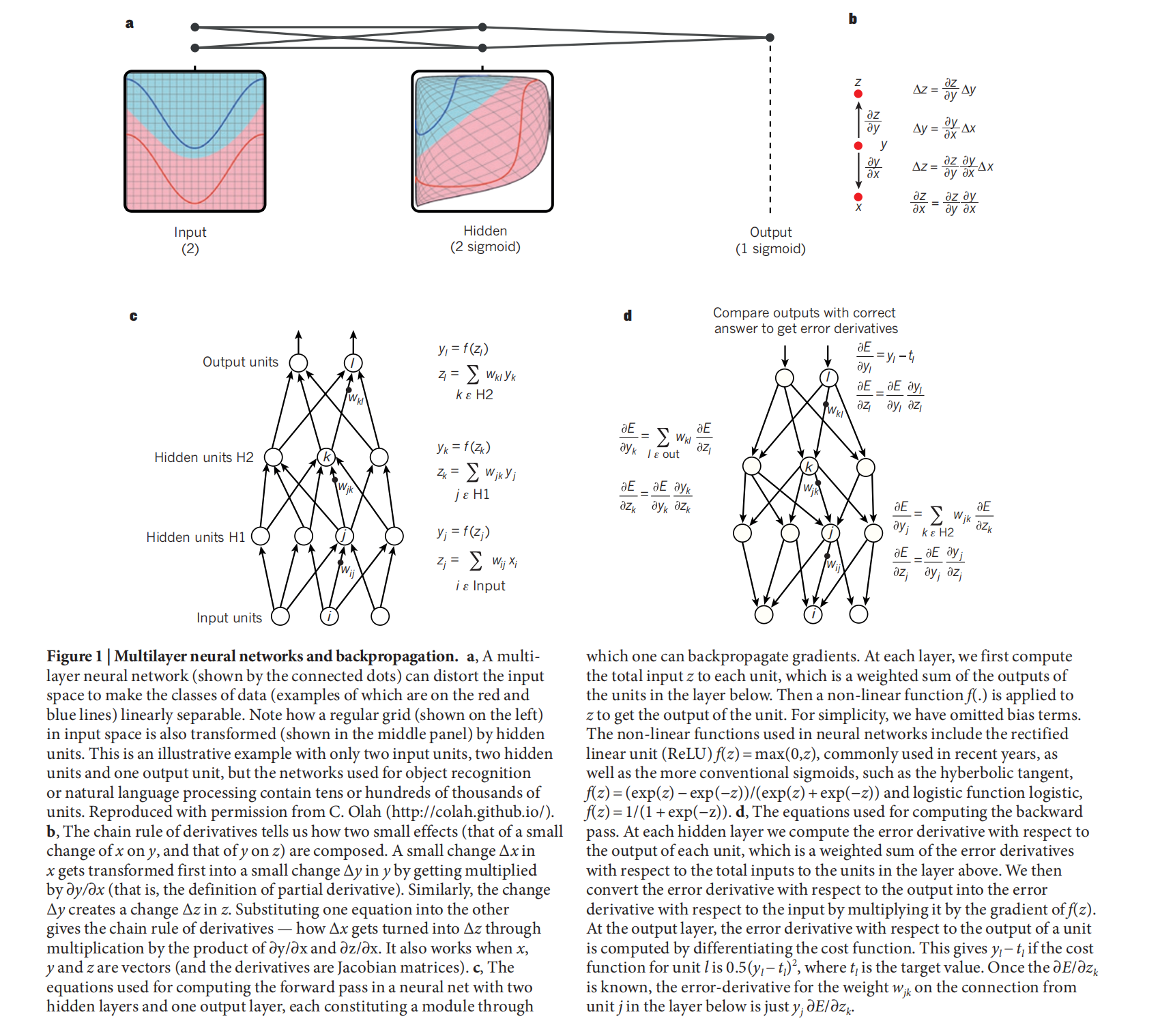
Backpropagation to train multilayer architectures
Convoluational neural networks
The reason of Convolution Layer architecture is twofold:
- In array data such as images, local groups of values are often highly correlated, forming distinctive local motifs that are easily detected.
- The local statics of images and other signals are invariant to location. In other ward, if a motif can appear in one part of image, it could appear anywhere. Hence, the diea of units at different locations sharing the same weights and detect the same pattern in different parts of array.
The rold of the convolutional layer is to detect local conjunctions of features from the previous layer.
The reason of Pooling Layer architecture:
- Reducing the dimension of the representation.
- The relative positions of the features forming a motif can vary somewhat, so Pooling Layer create an invariance to small shifts and distortions.
Image understanding with deep convolutional networks
The reason of the success of ConvNet:
- ImageNet 2012(a million images that contained 1000 different classes)
- efficient use of GPU
- ReLU and dropuout
- Techniques to generate more trainging examples by deforming the existing ones.
Distributed representations and language processing
Method: Using context around a word.
Target: Learning word vector.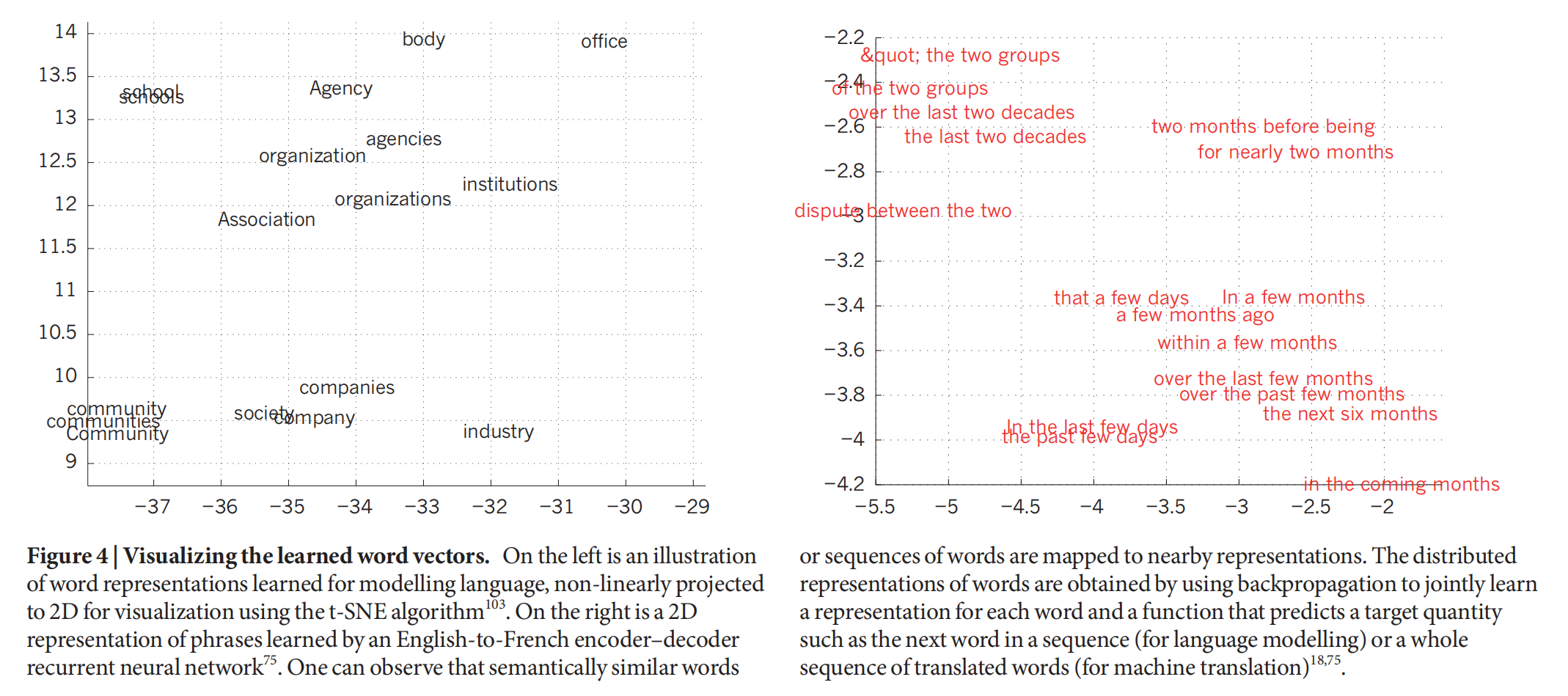
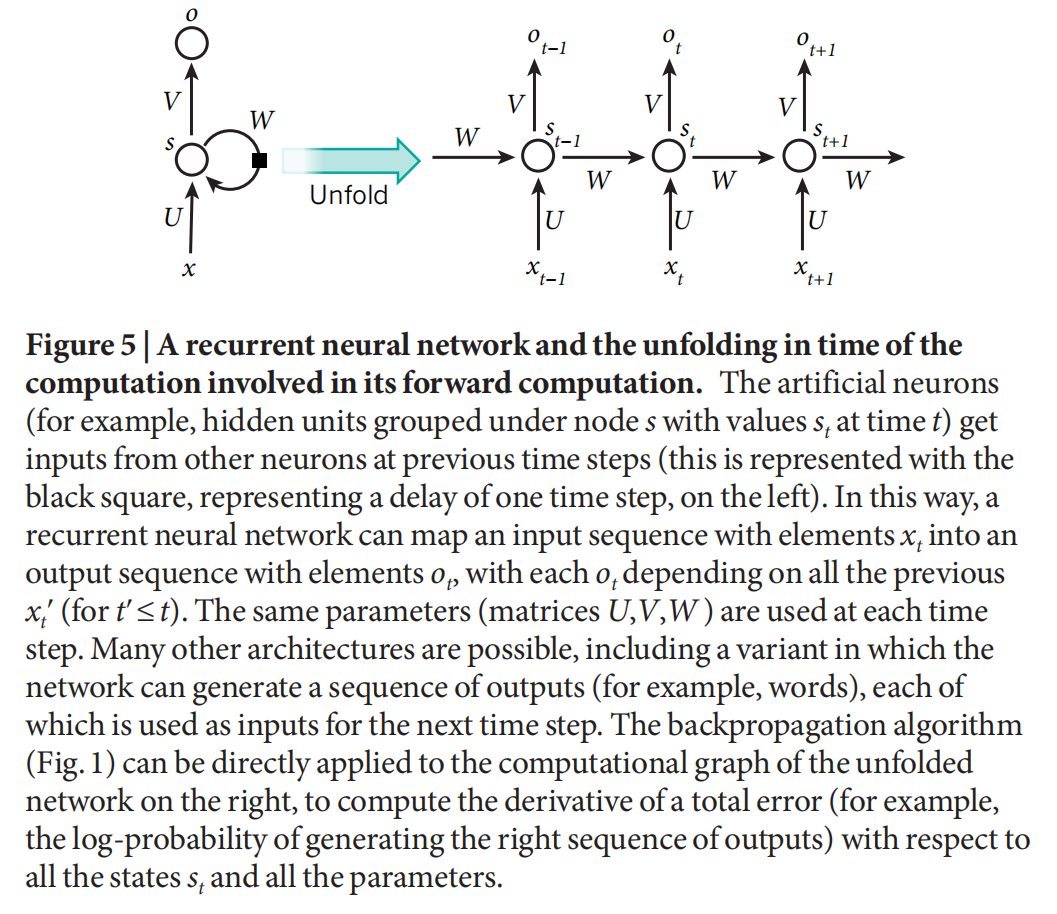
Recurrent neural networks
For task that involve sequential inputs(e.g. speech, text), RNN works better. Because when RNN maintain state vector(implicitly contains information about history) in a hidden unit. Unfold RNN in time can be seen as very deep neural network in which all the layers share the same weights.
Problem
- Gradient explode or vanish: In practice, trainging RNN can be problematic because the backpropagated gradients either grow or shrink at each time step.
- Hard to store information for very long: To correct for that, one idea is Long Short-Term Memory(LSTM). Many proposals about Augment RNNs with a memory module have published over past years.
Application
RNN + encoder-decoder structure can perform well in machine translation task. For example, after reading a English sentence one word at time, an English encoder can ve trained so that the final state is a good representation of the thought expressed by the sentence. This thouthg vector can be used as the initial hidden state(or as extra input) of a jointly trained French decoder, which outputs a probablity distribution for the first word of French translation.
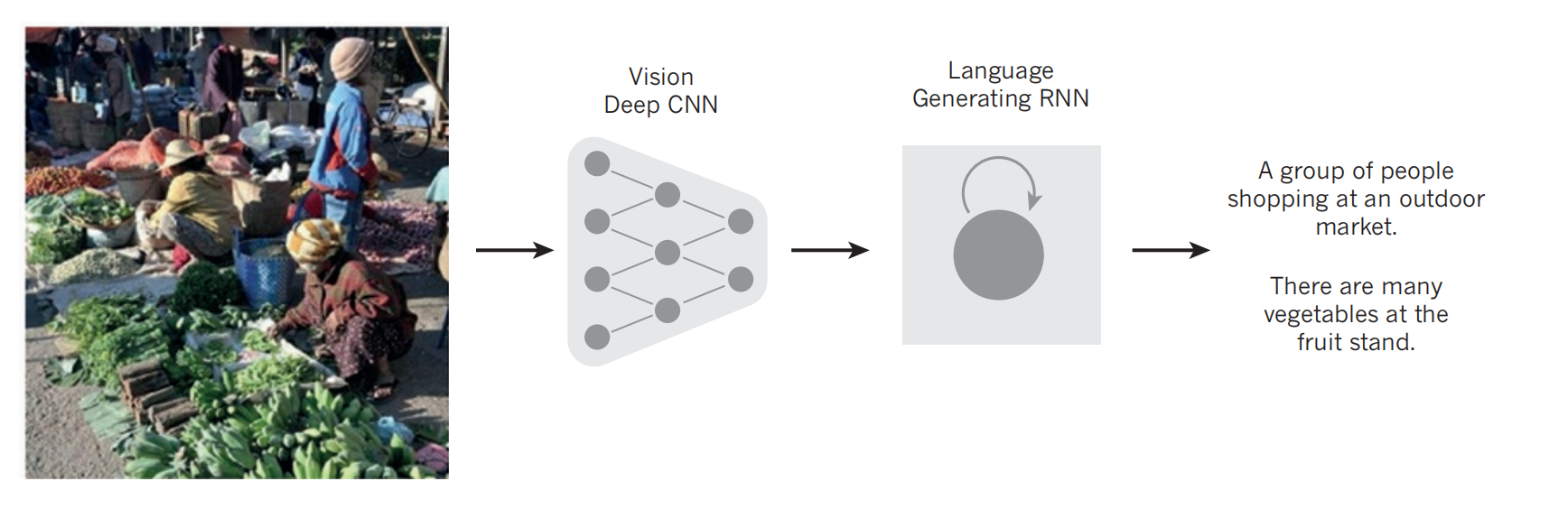
Instead of translating one language to another language, one can learn to translate the meaning of an image into a text. The encode here is a deep ConvNet that converts the pixels into an activity vector in its last hidden layer. The decoder is an RNN similar to one used for natural language modelling.
The future of deep learning
- Human and animal learning is largely unsupervised, we expect unsupervised learning to become far more important in the longer term.
- We exepct mush of the future progress in vision to come from systems that are trained end=to-end and combine ConvNet with RNNs that use reinforcement learning to decide where to look.
- We expect systems that use RNNs to understand sentences or whole documents will become much better when they learn stratefies for selectively attending to one part at a time.