^ _ ^
本文基于代码基于pytorch库.
Step1: 读取配置
template
1 | import argparse |
以上参数均可通过shell脚本进行传入
Step2: 构建一个日志记录器
日志记录器最好可以同时写控制台和文件
definition template
1 | # common.py |
use template
1 | from common import logger |
Step3: GPU设置
Setup CUDA, GPU & distrubuted training
基础
1 | # 为保证多次训练结果一致, 需要设置确定的随机数种子 |
拓展 – 分布式GPU
可以使用 torch.distributed 包进行单机多卡的GPU分布式训练.
1 | # 几个常见函数, 具体使用方法没有弄懂, 仅作罗列 |
Step4: 数据准备
一般而言, 不同的数据集需要的处理方法是不同的, 因此可以通过实现不同的Processor类来分别完成各个数据集的处理工作.
processor类调用方式
1 | # processor.py |
processor类的编写
基类编写
1 | class DataProcessor(object): |
DataProcessor类中主要针对两种ner输入文件格式进行解析, 返回类型均为 dict_list.
txt样板
1 | 吴 B-NAME |
json样板
1 | {"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {"name": {"叶老桂": [[9, 11]]}, "company": {"浙商银行": [[0, 3]]}}} |
以Cner数据集为例
1 | class InputExample(object): |
Step5: 加载预训练模型
加载方式
1 | from transformers import BertConfig, BertTokenizer |
预训练模型可以去 hugging face 官网上进行下载. 对于基于 pytorch 的预训练模型, 主要下载 config.json(对应BertConfig类的初始化), vocab.txt(对应BertTokenize类的初始化), pytorch.bin(对应预训练模型).
很多时候, 我们会在预训练模型之后增加一些神经网络层进行微调. 比如这个例子中,
BertCrfForNer就是由程序员编写, 而不是像BertConfig和BertTokenizer一样直接从transformers库中引用.
网络结构编写
1 | from .layers.crf import CRF |
其中, BertPreTrainedModel是一个抽象类, 包含_init_weights来处理参数初始化; BertModel 是一个基础的Bert网络架构, 需要通过 configs 传入一些参数. 不过这些参数不需要程序员设定, 可以直接从BertConfig中进行读取.
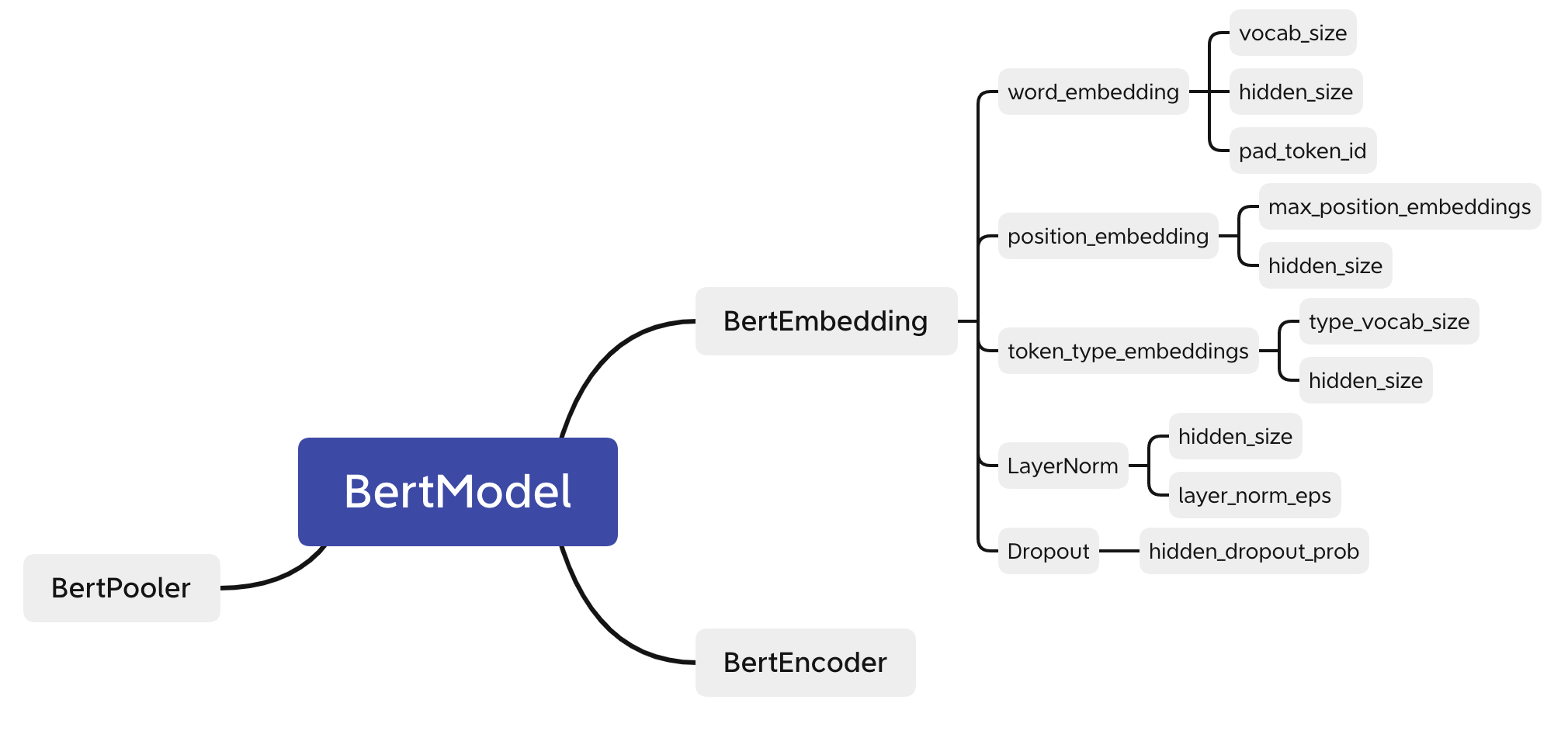
整个BertCrfForNer由两部分组成:
- 第一部分相当于一个分类模型. 输入一个词, 输出是这个词被标注为各个label的概率.
- 第二部分是CRF. 输入一段文本, 这个文本中每个词经过第一部分都会得到一个概率向量. 根据label之间的约束, 找到一条联合概率最大的路径作为输出结果, 即为输入文本对应的标注结果.
Classifier
bert –> dropout –> classifier
CRF
CRF可以继承torch.nn.Module类作为Bert层后的连接层. Bert层的输出是一个3维矩阵: $batch_size \times sequence_length \times label_nums$. 对于 sequence 中的每个词, 都会对应所有label 有一个特定的概率. 一种简单的做法是直接取概率最大的那个label作为该词的输出label. 但这种简单的方式忽略了 label 之间的依赖和约束关系. 比如 B-Product 标签后面一定不会再跟一个 B-Product. 而 CRF 层同时考虑了label之间的依赖约束关系和Bert层的到的概率矩阵.
CRF层中比较重要的几个变量是:
- start_transitions, end_transitions: 一维向量, 长度为 label_num , 分别表示每个 label 出现在句首和句尾的概率.
- transitions: 转移矩阵, shape 为 $label_num \times label_num$, mat[i, j]表示 label_i 后面跟 label_j 的概率.
- emissions: 发射矩阵, shape 为 $batch_size \times sequence_length \times label_nums$, 即 Bert 层输出结果.
以上三个矩阵都不需要人为设置, 其中start_transitions, end_transitions, transitions三个参数CRF层会在模型训练的过层中自动调整, 而emissions是Bert层传入的参数, 会在Bert层进行自动调整. 因此在CRF类中也需要定义forward函数, 传入主要参数包括 emissions(Bert层输出结果), tags(正确label序列), mask(元素类型为bool的大小为$label_num \time label_num$的矩阵, mat[i, j]表示label_i的下一个label是否可以为label_j).
指定模型训练GPU
1 | model.to(args.device) |
Step6: 加载数据
调用方式
1 | train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, data_type='train') |
load_and_cache_examples函数
如果数据已经缓存了, 就直接从缓存文件中读取出来; 否则, 利用之前编写好的 processor 类从源数据文件中读取并转换为需要训练的数据格式, 最后将数据写入缓存文件方便下次使用.
1 | def load_and_cache_examples(args, task, tokenizer, data_type='train'): |
在这个函数中包含的关键函数是convert_examples_to_features, 这个函数将[{words: char_list, labels: label_list}] 转换为 [{words: num_list, label: num_list}].
1 | import logging |
Step7: 模型训练
调用方式
1 | global_step, tr_loss = train(args, train_dataset, model, tokenizer) |
train函数编写
1 | def train(args, train_dataset, model, tokenizer): |
data_loader
1 | from torch.utils.data import DataLoader, RandomSampler, SequentialSampler |
Prepare optimizer and schedule
1.还原结构
1 | from callback.optimizater.adamw import AdamW |
2.还原optimizer和scheduler参数
1 | # Check if saved optimizer or scheduler states exist |
3.还原checkpoint数据
1 | global_step = 0 |
训练
1 | tr_loss, logging_loss = 0.0, 0.0 |
Step8: 保存最好的模型结果
1 | global_step, tr_loss = train(args, train_dataset, model, tokenizer) |
Step9: 在dev集上评估
1 | import glob |
evaluate函数
1 | def evaluate(args, model, tokenizer, prefix=""): |
其中比较关键的两个部件是SeqEntityScore(准确率计算类)和crf.decode(解码CRF结果矩阵的到最优tag路径).
SeqEntityScore
1 | class SeqEntityScore(object): |
crf.decode
1 | def _viterbi_decode(self, emissions: torch.FloatTensor, |
Step9: 在test集上预测
与evaluate基本一致