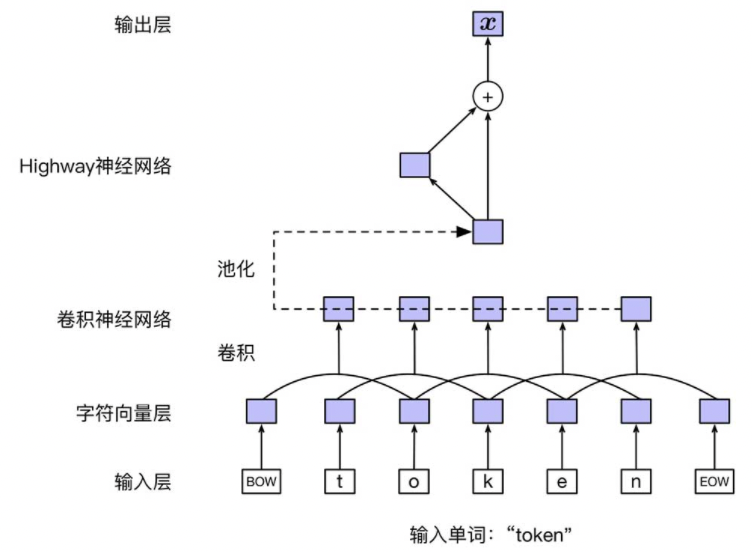
在静态词向量表示中,由于词的所有上下文信息都被压缩、聚合至单个向量表示内,因此难以刻画一个词在不同上下文或不同语境下的不同词义信息。为了解决这一问题,研究人员提出了上下文相关的词向量(Contextualized WordEmbedding)。顾名思义,在这种表示方法中,一个词的向量将由其当前所在的上下文计算获得,因此是随上下文而动态变化的,也将其称为 动态词向量(Dynamic Word Embedding)。
defload_corpus(path, max_token_len=None, max_seq_len=None): '''load data from text corpus and create vocabulary max_token_len: max length of a word max_seq_len: max length of a sequence ''' text = [] charset = {BOS_TOKEN, EOS_TOKEN, PAD_TOKEN, BOW_TOKEN, EOW_TOKEN} with open(path, "r") as f: for line in tqdm(f): tokens = line.rstrip().split(" ") # cut long sequence if max_seq_len isnotNoneand len(tokens) + 2 > max_seq_len: tokens = line[:max_seq_len-2] sent = [BOS_TOKEN] for token in tokens: if max_token_len isnotNoneand len(token+2) > max_token_len: token = token[:max_token_len-2] sent.append(token) for ch in token: charset.append(ch) sent.append(EOS_TOKEN) text.append(sent) # create word-level vocabulary vocab_w = Vocab.build(text, min_freq=2, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN]) # create char-level vocabulary vocab_c = Vocab(tokens=list(charset))
# create word-level corpus corpus_w = [vocab_w.convert_tokens_to_ids(sent) for sent in text] # create char-level corpus corpus_c = [] bow = vocab_c[BOW_TOKEN] eow = vocab_c[EOS_TOKEN] for i, sent in enumerate(text): sent_c = [] for token in sent: if token == BOS_TOKEN or token == EOS_TOKEN: token_c = [bow, vocab_c[token], eow] else: token_c = [bow] + vocab_c.convert_tokens_to_ids(token) + [eow] sent_c.append(token_c) corpus_c.append(sent_c) return corpus_w, corpus_c, vocab_w, vocab_c
defcollate_fn(self, examples): seq_lens = torch.LongTensor([len(ex[0]) for ex in examples]) # word-level input inputs_w = [torch.tensor(ex[0]) for ex in examples] # padding inputs_w = pad_sequence(inputs_w, batch_first=True, padding_value=self.pad_w) # calculate max(sentence) and max(word) batch_size, max_seq_len = inputs_w.shape max_token_len = max(max([len(token) for token in ex[1]]) for ex in examples)) # char-level input inputs_c = torch.LongTensor(batch_size, max_seq_len, max_token_len).fill_(self.pad_c) for i, (sent_w, sent_c) in enumerate(examples): for j, token in enumerate(sent_c): inputs_c[i][j][:len(token)] = torch.LongTensor(token) # forward-output & backward-output targets_fw = torch.LongTensor(inputs_w.shape).fill_(self.pad_w) targets_bw = torch.LongTensor(inputs_w.shape).fill_(self.pad_w) for i, (sent_w, sent_c) in enumerate(examples): targets_fw[i][:len(sent_w)-1] = torch.LongTensor(sent_w[1:]) targets_bw[i][1:len(sent_w)] = torch.LongTensor(sent_w[:len(sent_w)-1])\ return inputs_w, inputs_c, seq_lens, targets_fw, targets_bw