For pre-trained based on neural model, it only considered history information and ignored future information. So someone proposed some more efficient pre-trained word vecotr model, including CBOW(Continuous Bag-Of-Words) and Skip-Gram. They are not language model strictly, only basing co-occurrence information realize learning of word vecotr.
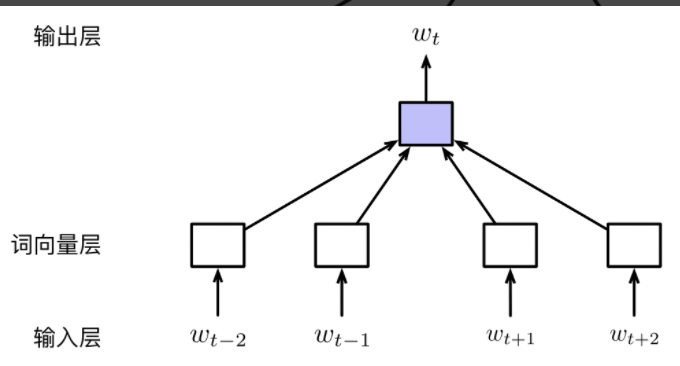
CBOW
The basic core idea of CBOW: According fixed length of window $|C_t|$(e.g. 5) look up text $w_{t-2}w_{t-1}w_{t}w_{t+1}w_{t+2}$. Based on the context word $C_t = {w_{t-2}, w_{t-1}, w_{t+1}, w_{t+2}}$, predicting $w_t$. The difference between CBOW and neural language model is: CBOW model dont’t consider the order or position of context words.
(1) Input Layer: Suppose the length of fixed window is n, then the dimension of input is $(n-1) \times |V|$, where $V$ is the vocabluary and every column in the input matrix is a word represented by one-hot encoding.
(2) Embedding Layer: Transfer input space to word vector space through matrix $E \in R^{d \times |V|}$: $v_{w_i} = Ee_{w_i}$. Suppose $C_t = {w_{t-k}, \cdots, w_{t-1}, w_{t+1}, \cdots, w_{t+k}}$. Then we calculate $v_{C_t} = \frac{1}{C_t}\sum_{w \in C_t}v_w$.
(3) Output Layer: $E’ \in R^{|V| \times d}$ is the transport matrix from hidden layer to output layer. Suppose $v’{w_i}$ in $E’$ is the correspoding row vecotr of $w_i$. The probablity of output $w_t$ is $P(w_t|C_t) = \frac{exp(v{C_t} \cdot v’{w_t})}{\sum{w’ \in V}exp(v_{C_t} \cdots v’_{w^’})}$.
In the CBOW model, both $E$ and $E’$ can apply as word vecotr matrix. In some task, we also can combine both to get better performance.
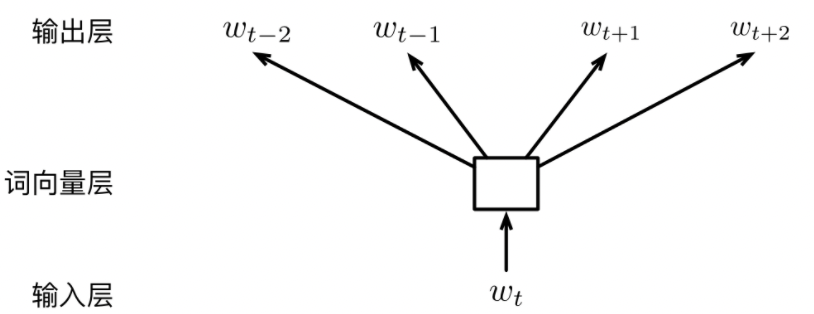
Skip-Gram
CBOW method using all the words in the context window to predict target word. Skip-Gram model simplified this process: using every word in context window dependently predict the target word. So Skip-Gram model try to establish the co-occurence realtionship between one word to one word, specifically $P(w_t|w_{t+j})$, where $j \in {\pm 1,\cdots,\pm k}$. It also can be described as predict context by current word, as $P(w_{t+j}|w_t)$.
In the Input Layer, current time word one-hot encoding $w_t$ as input will map itself from input layer to Embedding Layer through matrix E. Formually, $v_{w_t} = E^T_{w_t}$. Then we use linear transformation matrix $E’$ to predict context word in output layer: $P(c|w_t) = \frac{exp(v_{w_t} \cdot v’c)}{\sum{w’ \in V}exp(v’_{w’})}$.
Parameters Estimation
Both CBOW model and Skip-Gram model need to estimate paramters $\theta={E, E’}$. But they have different loss function:
For CBOW, $L(\theta) = -\sum_{t=1}^T logP(w_t|C_t)$
When the size of vocabulary is too big and the computing resources is limited, both CBOW model and Skip-Gram model will decrease computing efficiency because of the normalization process in the output layer. Negative Sampling provide a new task view: Given current word and its context, maxmize the probablity of co-occurence of them. After that, the problem can be simplified to another problem: binary classfication task according to $(w, c)$. The probability of $(w,c)$ has co-occurence relationship: $P(D=1|w,c) = \sigma(v_w \cdot v’_c)$. Otherwise, $P(D=0|w,c) = 1 - P(D=1|w,c) = \sigma(-v_w \cdot v’_c)$
In Skip-Gram model, $w=w_t, c=w_{t+j}$. If the pair $(w, c)$ satisfies co-occurence condition, then it is a positive sample. At the same time, we can do some negative samples based on this. We sampled some words which is not in the context word, marked as $\widetilde{w_{i}}$. The item $P(w_{t+j}|w_t)$ in loss function will be represented as $P(w_{t+j}|w_t) = log \sigma(v_{w_t} \cdot v’{t+j}) + \sum{i=1}^K log \sigma(- v_{w_t} \cdot v’_{\widetilde{w_i}})$. Usually, the negativate sampling can adapt a sort of distribution.
Code
CBOW
create dataset
1 2 3 4 5 6 7 8 9 10 11 12 13
classCbowDataset(Dataset): def__init__(self, corpus, vocab, context_size=2): self.data = [] self.bos = vocab[BOS_TOKEN] self.eos = vocab[EOS_TOKEN] for sentence in tqdm(corpus, desc="Dataset Construction"): sentence = [self.bos] + sentence + [self.eos] if len(sentence) < context_size * 2 + 1: continue for i in range(context_size, len(sentence)-context_size): context = sentence[i-context_size:i] + sentence[i+1:i+context_size+1] target = sentence[i] self.data.append((context, target))