^ _ ^
Pre-trained Word Vector Task
Given a text $w_1w_2\cdots w_n$, the basic task of language model is to predict the possibility of one word occures in one position. In other word, calculating conditional probablity $P(w_t|w_1w_2\cdots w_{t-1})$.
To consturct Language Model, we can transfer the problem to a classification problem: the input is history word sequence($w_{1:t-1}$), the output is $w_t$. Then, we can use text which is non-labeled to consturct training dataset and train the model by optimizer loss function in this dataset. Since the supervised signal came from the data itself, this type of learning is also called Self-supervised Learning.
Feed-forward Neural Netword Language Model
Bias Hypothesis: Markov Assumption
The prediction of the next word is only associated with the most recent n-1 word in history.
Formually: $P(w_t|w_{1:t-1}) = P(w_t|w_{t-n+1:t-1})$
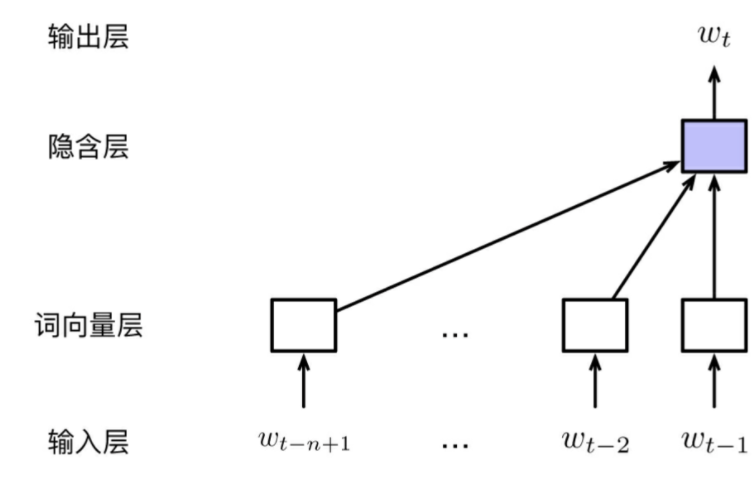
(1) Input Layer: In the current time $t$, every input is composed of history word sequence $w_{t-n+1:t-1}$. Specifically, we can use One-Hot Encoding or Vocabulary Index to present a word.
(2) Embedding Layer: Embedding Layer maps every word in input layer to a dense vector which called feature vector. In other view, Embedding Layer can be viewed as a Look-up Table. The process of get word vector can be viewed as a process of search the vector in Look-up Table according to the index of the word.
Formually, $x = [v_{w_{t-n+1}}; \cdot; v_{w_{t-2}};v_{w_{t-1}}]$, where
- $v_w \in R^d$: shows the word vecotr of d dimenion
- $x \in R^{(n-1)d}$: shows the result of concating all the word vector in history sequence.
We can define word vector matrix $E \in R^{d \times |V|}$, where $V$ is the vocabulary.
(3) Hidden Layer: Linear Transform and Activation to $x$ in Embedding Layer. $h=f(W^{hid}x + b^{hid})$.
- For Linear transform, $W^{hid} \in R^{m \times (n-1)d}$ is the linear transformation matrix from embedding layer to hidden layer.
- For Activation, normally activation function contains Sigmoid, tanh, ReLU.
(4) Output Layer: Linear Transform and Softmax to get probability distribution of Vocabulary. $y = Softmax(W^{out}h + b^{out}$, where $W^{out} \in R^{|V| \times m}$ is the linear transforamtion matrix from hidden layer to output layer.
From what has been discussed above, the parameters of FNN can be represented as $\theta = {E, W^{hid}, b^{hid}, W^{out}, b^{out}}$. The number of parameters is $|V| \times d + m \times (n-1)d + m + |V| \times m + |V|$. And in case of $m$ and $d$ are constant, so the number of parameter will increase linearly according to the size of vocabulary.
Besides, the optimization of hyperparameter such as dimension of word vector d, hidden units dimension m, input sequence length n-1, should be modified by the development dataset.
After the training, matrix $E$ will be the Static Word Vecotr which is pre-trained.
Recurrent Nerual Network Language Model
In the FNN LM, the prediction of next word is depended by the length of history be looked back(parameter n). But in the reality situation, the expectation of n is different because of the different length of sequences. For example, “我吃_“, the word in “_“ should be food can be infered by “吃”, only considering short history. But “他感冒了,于是下班之后去了_“, the word in “_“ should be hospital can be infered by “感冒”, that needs to consider long history.
RNN LM has a good nature to deal with the dependency relationship which has unfixed length. RNN maintains a hidden state, which is called Memory, contains all the history information of current word in every moment. Memory and current word will joint together as the input of the next time.
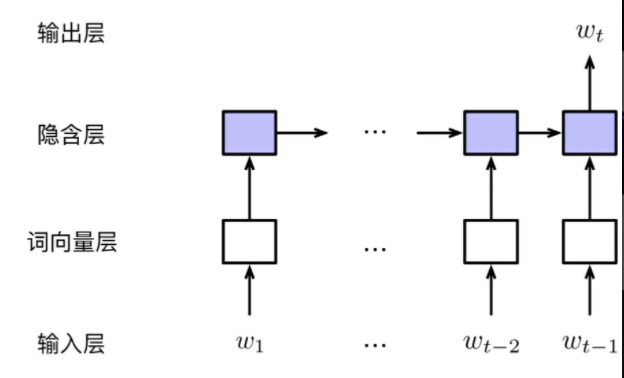
(1) Input Layer: the input in RNN LM is not limited by the window length n any more. It can be represented by the whole history sequence, $w_{1:t-1}$.
(2) Embedding Layer: Like FNN LM, in the Embedding Layer, the input sequence should map to word vector. In RNN, every input of time t should be composed of 2 part: Memory, hidden state $h_{t-1}$; the previous word $w_{t-1}$. Specifically, we add start tag <bos> as $w_0$; zero vector as init hidden state $h_0$. The input of t can be represented as $x_t= [v_{w_{t-1}}; h_{t-1}]$.
(3) Hidden Layer: Like FNN LM, the calculation of Hidden Layer is composed of Linear Transform and Activation Function. $h_t = tanh(W^{hid}x_t + b^{bid})$, where $W_{hid} \in R^{m \times (d+m)}, b^{hid} \in R^m$. For detailed, $W^{hid}=[U; V]$, where $U \in R^{m \times d}, V \in R^{m \times m}$. So another formula has the same meaning, $h_t = tanh(Uv_{w_{t-1}} + Vh_{t-1} + b^{hid})$.
(4) Output Layer: $y_t = Softmax(W^{out}h_t + b^{out})$, where $W^{out} \in R^{|V| \times m}$.
When the input sequence is too long, Vanishing Gradient and Exploding Gradient might occurred. To deal with this problem:
- Before 2015, Truncated Back-propagation Through Time is the mainstream method.
- After 2015, Gating Mechanism is the mainstream method.(e.g. LSTM)
Code
Load Data
load corpus and create vocab
1 | BOS_TOKEN = "<bos>" # sentence head tag |
FNN
create dataset for FNN
1 | class NGramDataset(Dataset): |
FNN LM
1 | class FeedForwardNNLM(nn.Module): |
Training
1 | embedding_dim = 128 |
Save model
1 | def save_pretrained(vocab, embeds, save_path): |
RNN
create dataset for RNN
1 | class RnnlmDataset(Dataset): |
create RNN model
1 | class RNNLM(nn.Module): |
Training
1 | embedding_dim = 128 |
Since the goal of training is to acquire the word vector rather than language model itself. In the training process, it is not necessary to take the convergency state of the model as the termination condition of training.