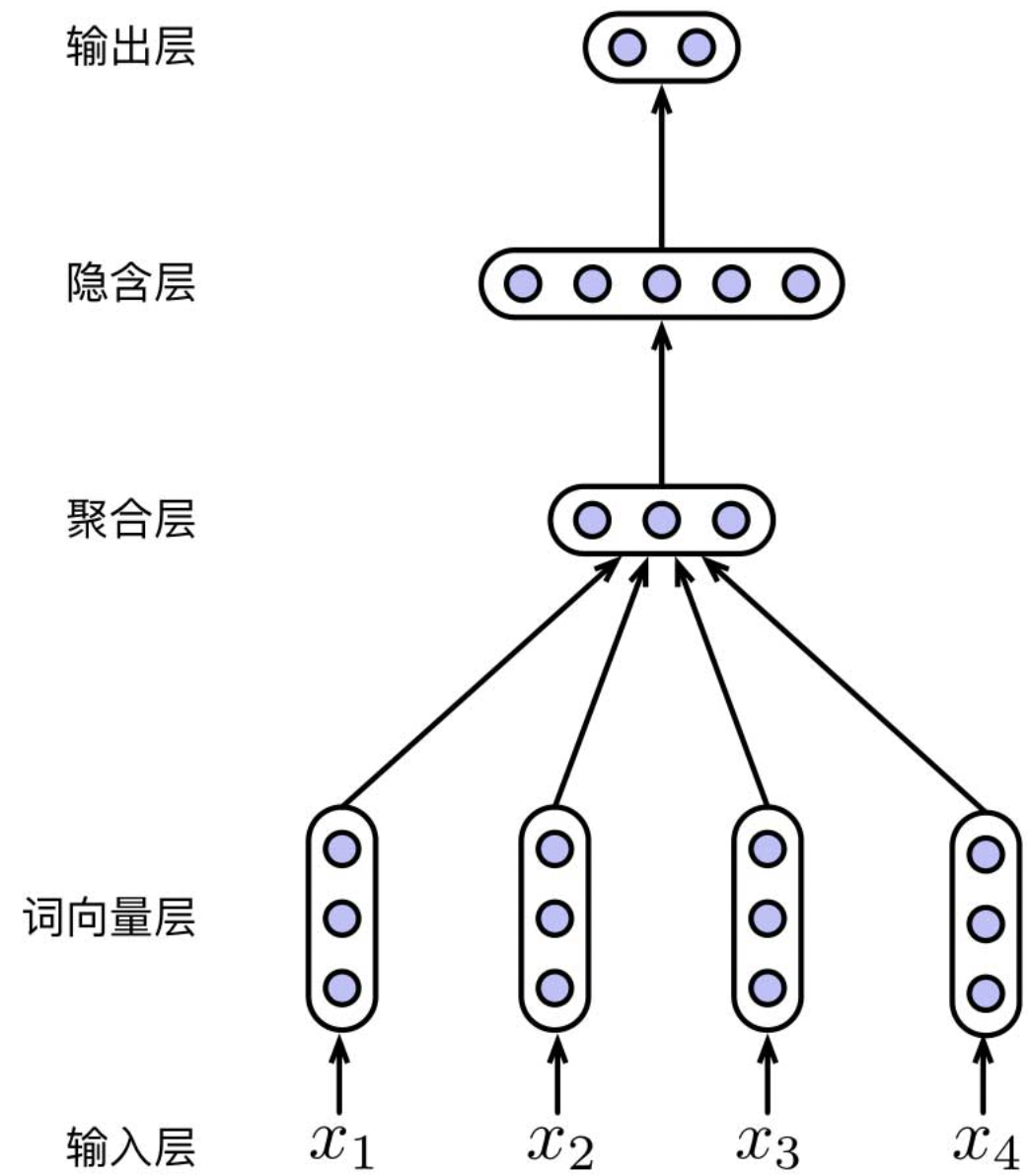
Usually, we need to trans word to word embedding vector first, then take the embedding vector as the input of MLP network. But a sequence usually contains many word vectors. The problem is How can we take them as the input vector of MLP? One way is Concating the n vectos as a new vector whose dimension is $n \times d$. By the way, $d$ is the dimension of word vector. But this way will cause a problem: The final prediction results are too related with the position of tokens in sequence. If add a new token in the head of sequence, then all parameters of network will change and the results will be much different.
To solve this problem, we can use Bag Of Words. In BOW method, we don’t consider the order of words in the sequence, and simply view the sequence as a set of words. So, we can use aggregation to process many word vectors in one sequence, such as average, sum, max.
However, in real situation, input sequences in one batch often have different length. In other word, sometimes the input can not be represented by a matrix because of different sequence length. A solution for this problem is EmbeddingBag:
Firstly, Concating all the sequences.
Finally, Using Offsets to record every start position of every sequence.
1 2 3 4 5 6 7 8 9
# Suppose every input_i has different length inputs = [input1, input2, input3, input4] offsets = [0] + [i.shape[0] for i in inputs] offsets = torch.tensor(offsets[:-1].cumsum(dim=0)) inputs = torch.cat(inputs)
from torch.utils.data import DataLoader ''' DataLoader(dataset, batch_size, collate_fn, shuffle) - dataset: a subclass of torch.utils.data.Dataset - collate_fn: transform function applies in one mini-batch. e.g. transform origin data to tensor '''
# dataset example classBowDataset(Dataset): def__init__(self, data): # data is the original data self.data = data def__len__(self): return len(self.data) def__getitem__(self, i): return self.data[i]
# collate_fn example ''' examples is a mini-batch of dastaset suppose data structure is (sentence, polarity) through collate_fn, we will transfer it to an input tensor ''' defcollate_fn(examples): inputs = [torch.tensor(ex[0]) for ex in examples] targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long) offets = [0] + [i.shape[0] for i in inputs] offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) inputs = torch.cat(inputs) return inputs, offsets, targets
from torch.nn.utils.rnn import pad_sequence defcollate_fn(examples): inputs = [torch.tensor(ex[0]) for ex in examples] targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long) # padding every sequence to the same length, default char is '0' inputs = pad_sequence(inputs, batch_first=True) return inputs, targets
LSTM
In the BOW(Bag-Of-Word) machenism, we ignore the order of sequence. For example, pharase “张三打李四” is equal to “李四打张三” in the BOW. So BOW is not reasonable in some situations. To avoid this defect, we can use RNN, specially LSTM.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from torch.nn.utils.rnn import pack_padded_sequence
defcollate_fn(examples): lengths = torch.tensor([len(ex[0]) for ex in examples]) inputs = [torch.tensor(ex[0]) for ex in examples] targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long) inputs = pad_sequence(inputs, batch_first=True) return inputs, lengths, target
classPositionalEncoding(nn.Module): def__init__(self, d_model, dropout=0.1, max_len=512): super(PositionalEncoding, self).__init__() pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exo(torch.arange(0, d_model, 2).float() * (-math.log(10000.0)/d_model)) # position encoding for even position pe[:, 0::2] = torch.sin(position * div_term) # position encoding for odd position pe[:, 1:2] = torch.cos(position * div_term) pe = pe.unsqueeze(0).transpose(0, 1) # no gradient operation in positiong embedding self.register_buffer('pe', pe) defforward(self, x): x = x + self.pe[:x.size(0), :] return x