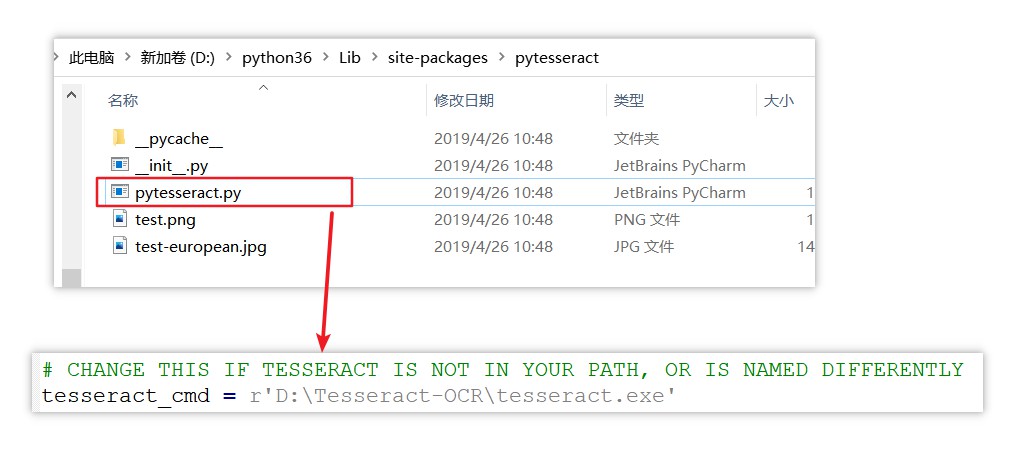
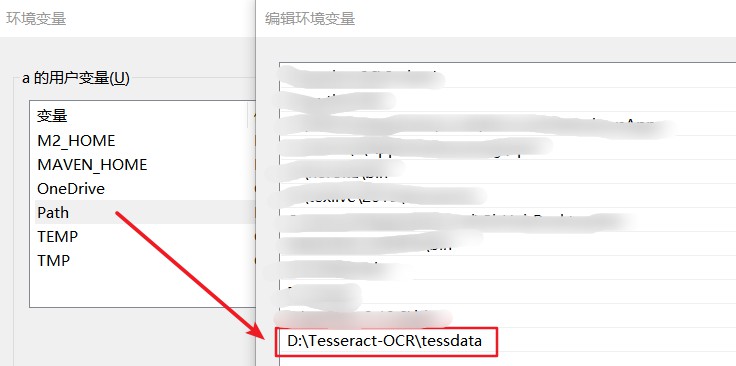
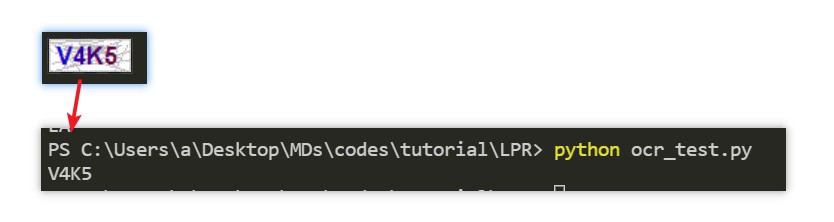
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| import cv2 as cv
import imutils
import numpy as np
import pytesseract
def preprocess(img):
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
gray = cv.bilateralFilter(gray, 13, 15, 15)
return gray
def edge_detect(img):
edged = cv.Canny(img, 30, 200)
return edged
def contour_detect(img, edged):
contours = cv.findContours(edged.copy(), cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv.contourArea, reverse = True)[:10]
copy_img = img.copy()
cv.drawContours(copy_img, contours, -1, (0, 0, 255), 3)
return contours
def position(img, contours):
screenCnt = []
for c in contours:
peri = cv.arcLength(c, True)
approx = cv.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt.append(approx)
if len(screenCnt) != 0:
cv.drawContours(img, screenCnt, -1, (0, 255, 0), 3)
return screenCnt[0]
else:
print("No contour detected")
return None
def extract_card(gray, card_contour):
mask = np.zeros(gray.shape, np.uint8)
cv.drawContours(mask, [card_contour], 0, 255, -1)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
card = gray[topx:bottomx+1, topy:bottomy+1]
return card
def ocr_card(card):
cv.imshow("card", card)
text = pytesseract.image_to_string(card, config='--psm 11')
print(text)
return text
def draw_text(text):
img = np.zeros((100,300,3), np.uint8)
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(img, text, (50,50), font, 1, (0,255,0), 3)
cv.imshow("text", img)
if __name__ == "__main__":
img = cv.imread('car1.jpeg', cv.IMREAD_COLOR)
img = cv.resize(img, (600, 400))
gray = preprocess(img)
edged = edge_detect(gray)
contours = contour_detect(img, edged)
card_contour = position(img, contours)
card = extract_card(gray, card_contour)
text = ocr_card(card)
draw_text(text)
cv.waitKey(0)
|