^_^
分类问题
在分类问题中,我们尝试预测的是结果是否属于某一个类(例如正确或错误),即预测值为离散值。如果我们要用线性回归算法来解决一个分类问题,对于分类,$y$取值为 0 或者1,但如果你使用的是线性回归,那么假设函数的输出值可能远大于 1,或者远小于0。尽管我们知道标签应该取值0 或者1,但是如果算法得到的值远大于1或者远小于0的话,就会感觉很奇怪。所以我们在接下来的要研究的算法就叫做逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。
逻辑回归模型
我们引入一个新的模型,逻辑回归,该模型的输出变量范围始终在0和1之间。 逻辑回归模型的假设是:$h_\theta = g(\theta^TX)$。其中,$X$代表特征向量,$g$代表逻辑函数(logistic function)。一个常用的逻辑函数为S形函数(Sigmoid function),公式为:$g(z) = \frac{1}{1+e^{-z}}$
该函数的图像为: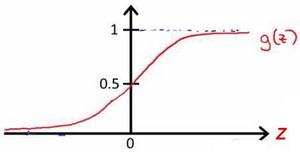
$h_\theta(x)$的作用是,对于给定的输入变量,根据选择的参数计算输出变量=1的可能性,即$h_\theta(x) = P(y=1|x;\theta)$。
判定边界
现在讲下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。

根据上面绘制出的 S 形函数图像,我们知道当
- $z=0$时,$g(z)=0.5$;
- $z<0$时,$g(z)<0.5$;
- $z>0$时,$g(z)>0.5$;
又有$z=\theta^Tx$,现在假设我们有一个模型: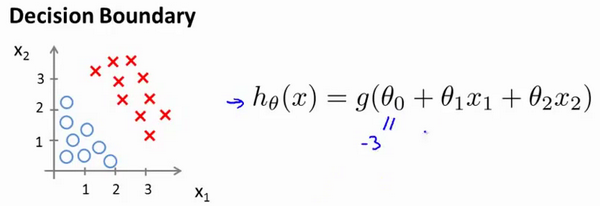
假设参数$\theta = [-3,1,1]$,则当$-3 + x_1 + x_2 > 0$时,模型将预测$y=1$。我们可以绘制直线$x_1 + x_2 = 3$,这条线便是我们模型的分界线,将预测为1的区域和预测为 0的区域分隔开。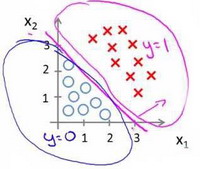
假使我们的数据呈现这样的分布情况,怎样的模型才能适合呢?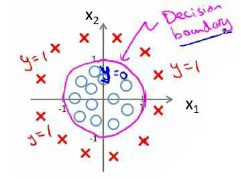
因为需要用曲线才能分隔$y=0$的区域和$y=1$的区域,我们需要二次方特征:$h_\theta(x)=g(\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1^2+\theta_4x_2^2)$。假设参数$\theta = [-1,0,0,1,1]$,,则我们得到的判定边界恰好是圆点在原点且半径为1的圆形。
我们可以用非常复杂的模型来适应非常复杂形状的判定边界。