^ _ ^
Q & A
Java中有哪些Map类,都有些什么区别?
- HashMap:
- 它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的;
- HashMap最多只允许一条记录的键为null,允许多条记录的值为null;
- HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致;
- LinkedHashMap:
- LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的;
- 也可以在构造时带参数,按照访问次序排序(LRU);
- TreeMap:
- TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的;
- 在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常;
- ConcurrentHashMap:
- ConcurrentHashMap引入了分段锁;
- 是线程安全的,并发性优于Hashtable。
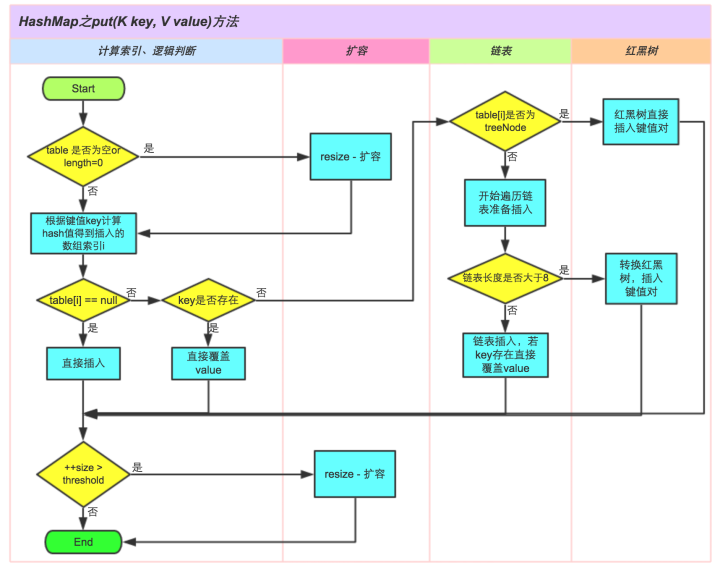
HashMap的实现原理是什么?
- 储存结构:
- 数组+链表+红黑树(JDK1.8增加了红黑树部分,即当链表长度超过8时转换为红黑树);
- Java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把数据放在对应下标元素的链表上;
- 存储的数据元实现了Map.Entry接口,本质是就是一个映射(键值对)。
- 功能实现:
- 确定哈希桶数组索引位置:取key的hashCode值、高位运算、取模运算
- put方法:将一个键值对插入hash表中
- 扩容机制:当hash表中元素总数超过阈值(threshold = 容量 * 负载因子)时进行扩容,一般是扩容为原来的一倍。扩容后需要重新计算各个元素在hash表中的位置。
HashMap在多线程下的安全问题是如何解决的?
用以下几种支持并发的类来代替HashMap:
- 使用Collections.SynchronizedMap(Map)创建线程安全的map集合;
- Hashtable
- ConcurrentHashMap
SynchronizedMap、HashTable、ConcurrentHashMap实现原理
- SynchronizedMap:内部维护了一个普通对象Map,还有排斥锁mutex,每次执行操作时,通过
synchronized(mutex)上锁 - HashTable:对数据操作的方法都用synchronized进行修饰;
- ConcurrentHashMap:在jdk1.7中是通过分段锁进行实现,在jdk1.8中通过CAS + synchronized来实现。
HashTable和HashMap的不同
- 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
Dictionary 是 JDK 1.0 添加的,貌似没人用过这个,我也没用过。 - 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
JAVA8的ConcurrentHashMap为什么放弃了分段锁?